Vall-E
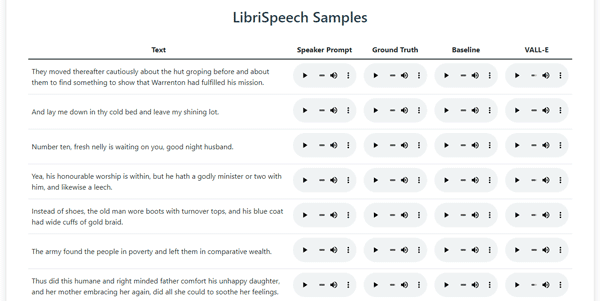
Vall-E is a language modeling approach for text to speech synthesis, designed.
Vall-E is a language modeling approach for text to speech synthesis, designed for individuals and organizations seeking high-quality, personalized speech synthesis. It is particularly useful for applications where speaker similarity and emotion preservation are crucial. Vall-E's neural codec language model is trained on 60K hours of English speech, enabling it to learn in-context and synthesize speech with only a 3-second enrolled recording of an unseen speaker. The model's capabilities include preserving the speaker's emotion and acoustic environment, making it suitable for various use cases. Vall-E is ideal for content creators, voice actors, and developers who need to generate realistic speech for their projects, as it offers a high level of customization and naturalness.
| Tool | Pricing | Upvotes | Rating |
|---|---|---|---|
 Read AI
Read AI |
Freemium | ▲ 112 | ★ 3.7 |
 BigIdeasDB
BigIdeasDB |
Freemium | ▲ 315 | ★ 3.5 |
 Juice AI
Juice AI |
Freemium | ▲ 280 | ★ 4.1 |