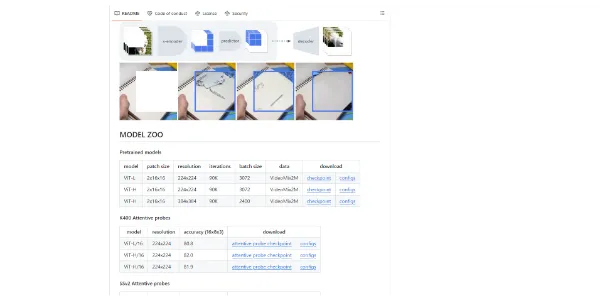
V-JEPA by Meta
V-JEPA by Meta is a PyTorch code and models for self-supervised learning.
V-JEPA by Meta is a PyTorch code and models for self-supervised learning from video, designed for researchers and developers working with video datasets. It allows for pretraining and evaluations on various video formats. The codebase includes tools for data preparation, model definitions, and utilities for launching distributed training and evaluations. V-JEPA's key capabilities include its ability to work with many standard video formats and its conditional diffusion model for decoding feature-space predictions to interpretable pixels. This makes it particularly useful for video classification tasks where interpretability is crucial. Researchers and developers in the field of computer vision can leverage V-JEPA by Meta to analyze and understand video data without extensive labeled datasets, thereby reducing the need for large-scale manual annotation.
| Tool | Pricing | Upvotes | Rating |
|---|---|---|---|
 Read AI
Read AI |
Freemium | ▲ 112 | ★ 3.7 |
 BigIdeasDB
BigIdeasDB |
Freemium | ▲ 315 | ★ 3.5 |
 Juice AI
Juice AI |
Freemium | ▲ 280 | ★ 4.1 |