QVQ by Qwen
QVQ by Qwen is an open-weight model designed for multimodal reasoning, aiming.
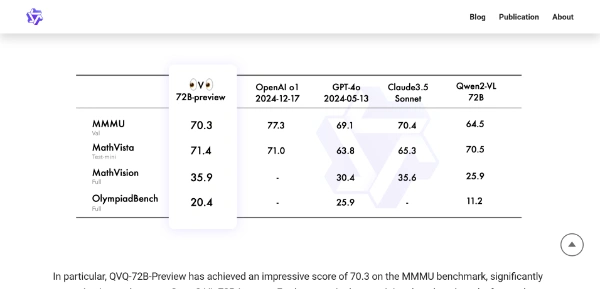
QVQ by Qwen is an open-weight model designed for multimodal reasoning, aiming to extend the capabilities of large language models by harnessing the power of visual understanding. It is particularly suited for individuals and teams involved in complex problem-solving tasks that require both linguistic and visual analysis. QVQ represents a significant leap forward in AI's capacity for visual understanding, achieving a score of 70.3 on the MMMU benchmark and showing substantial improvements across math-related benchmarks. The model demonstrates enhanced capabilities in visual reasoning tasks, especially in domains that demand sophisticated analytical thinking. QVQ's development is part of a broader vision to create an omni and smart model that integrates multiple modalities for deep thinking and reasoning based on visual information. By enhancing its vision-language foundation model with advanced capabilities, QVQ is poised to address complex challenges and engage in scientific exploration more effectively. The primary beneficiaries of QVQ are researchers, scientists, and educators who can leverage its capabilities to solve complex problems, analyze data, and develop new insights in fields like physics, mathematics, and science.
| Tool | Pricing | Upvotes | Rating |
|---|---|---|---|
 Read AI
Read AI |
Freemium | ▲ 112 | ★ 3.7 |
 BigIdeasDB
BigIdeasDB |
Freemium | ▲ 315 | ★ 3.5 |
 Juice AI
Juice AI |
Freemium | ▲ 280 | ★ 4.1 |