PIXART-α
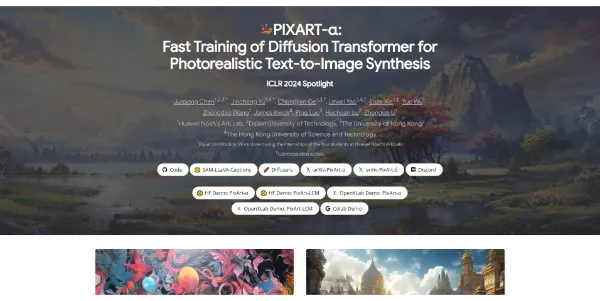
PIXART-α is a Transformer-based text-to-image diffusion model designed for generating high-fidelity images
PIXART-α is a Transformer-based text-to-image diffusion model designed for generating high-fidelity images. It can be combined with Dreambooth and given a few images and text prompts, it can produce images that exhibit natural interactions with the environment and precise modification of object colors. PIXART-α is suitable for individuals and organizations looking to generate high-quality images with customized extensions.
PIXART-α works by utilizing three core designs: training strategy decomposition, an efficient T2I Transformer, and high-informative data. The training strategy decomposition involves optimizing pixel dependency, text-image alignment, and image aesthetic quality separately. The efficient T2I Transformer incorporates cross-attention modules to inject text conditions and streamline computation-intensive class-condition branches. High-informative data is emphasized, and a large Vision-Language model is used to auto-label dense pseudo-captions to assist text-image alignment learning.
PIXART-α provides the most value to professionals and researchers in the field of AI image generation, particularly those looking for a model that can generate high-quality images at a low training cost. Its ability to produce images with exceptional quality and strong customization capabilities makes it an ideal tool for various applications, including art, design, and advertising.
| Tool | Pricing | Upvotes | Rating |
|---|---|---|---|
 Read AI
Read AI |
Freemium | ▲ 112 | ★ 3.7 |
 BigIdeasDB
BigIdeasDB |
Freemium | ▲ 315 | ★ 3.5 |
 Juice AI
Juice AI |
Freemium | ▲ 280 | ★ 4.1 |