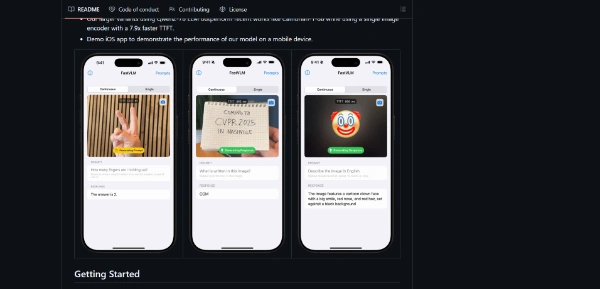
FastVLM by Apple
FastVLM by Apple is a vision language model designed to enable visual.
FastVLM by Apple is a vision language model designed to enable visual understanding alongside textual inputs. It is built by passing visual tokens from a vision encoder to a language model, making it suitable for developers and researchers working on applications that require scene analysis, such as visual content search and image recognition. FastVLM is faster and more accurate than popular vision language models of the same size, thanks to its hybrid vision encoders that deliver the best accuracy-latency tradeoff. The model is based on FastViTHD, an optimal vision encoder for vision language models that produces fewer but higher-quality visual tokens. This results in a better accuracy-latency tradeoff compared to other vision encoders, with FastVLM being up to 3x faster for the same accuracy. The model's performance is also compared to other popular vision language models, with FastVLM being significantly faster and more accurate. For instance, it is 85x faster than LLava-OneVision and 5.2x faster than SmolVLM. FastVLM's efficiency and accuracy make it a valuable tool for various applications, including document analysis, UI recognition, and answering natural language queries about images. Its ability to handle high-resolution images without sacrificing accuracy is particularly useful for tasks that require detailed understanding. Overall, FastVLM by Apple is an efficient and accurate vision language model that can be used in a variety of applications, from scene analysis to image recognition.
| Tool | Pricing | Upvotes | Rating |
|---|---|---|---|
 Read AI
Read AI |
Freemium | ▲ 112 | ★ 3.7 |
 BigIdeasDB
BigIdeasDB |
Freemium | ▲ 315 | ★ 3.5 |
 Juice AI
Juice AI |
Freemium | ▲ 280 | ★ 4.1 |