WeDLM
WeDLM is a diffusion decoding framework designed for fast inference, making it.
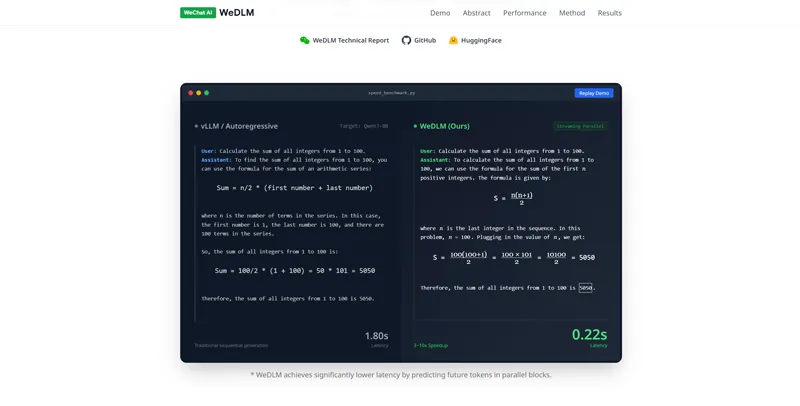
WeDLM is a diffusion decoding framework designed for fast inference, making it suitable for large language models and industrial applications. It achieves this by using standard causal attention, enabling parallel generation and prefix-cache friendly operations. WeDLM's core idea is to let each masked position condition on all currently observed tokens while keeping a strict causal mask.
WeDLM works by introducing a streaming decoding procedure that continuously commits confident tokens into a growing left-to-right prefix and maintains a fixed parallel workload. This approach avoids the stop-and-wait behavior common in block diffusion methods, allowing for substantial speedups over optimized AR engines. The framework also includes a dynamic sliding window that eliminates pipeline bubbles and enables 'noisy' tokens to attend to known futures via standard masks.
WeDLM is particularly valuable for developers and researchers working with large language models, as it preserves the quality of strong AR backbones while delivering speedups of up to 10× in low-entropy generation regimes. Its ability to outperform optimized AR engines in practice makes it an attractive solution for applications requiring fast and accurate text generation.
| Tool | Pricing | Upvotes | Rating |
|---|---|---|---|
 Read AI
Read AI |
Freemium | ▲ 112 | ★ 3.7 |
 BigIdeasDB
BigIdeasDB |
Freemium | ▲ 315 | ★ 3.5 |
 Juice AI
Juice AI |
Freemium | ▲ 280 | ★ 4.1 |